
Why AI Cannot Measure Willingness to Pay

The Evidence-Based Case for Primary Pricing Research in the Age of Generative AI
By Per Sjofors, "The Price Whisperer"
Founder & CEO, Sjofors & Partners | Author, The Price Whisperer: A Holistic Approach to Pricing Power
April 2026
---
Executive Summary
For the average company, a 1% increase in pricing typically results in an 11% rise in operating profit (an easy calculation every company executive must do; see example below). Despite its impact, most companies do not fully leverage pricing as a profit driver.

In 2025-2026, more companies are turning to ChatGPT, Claude, and other large language models for pricing guidance, often replacing primary market research with AI-generated estimates. The appeal is clear: immediate answers, no cost, and no survey logistics.
However, this approach entails significant and predictable risks.
This document delivers peer-reviewed evidence supporting a straightforward thesis:
AI can analyze historical pricing data, but it cannot measure willingness to pay (WTP). No validated methodology exists for generating reliable WTP estimates for new products, price points, or segments without collecting primary data from real buyers and non-buyers in B2C or B2B.
This is not an anti-AI argument. Sjofors & Partners uses AI extensively — our Predictive Demand Engine™ applies advanced clustering methods, AI-powered data quality screening, and machine learning to identify concealed patterns in primary research data. AI makes our research more powerful, more comprehensive, more practical and more detailed.
However, AI cannot replace primary research. The following sections explain why.
---
1. The $1.1 Trillion Question
Every year, companies leave an estimated $1.1 trillion in value on the table through pricing errors (Simon-Kucher Global Pricing Study). Most pricing decisions are still based on three unreliable inputs: assumptions, competitor benchmarks, and cost-plus margins.
A fourth unreliable input has emerged: reliance on AI for pricing decisions.
The appeal is understandable. Generative AI has transformed content creation, code generation, and data synthesis. However, pricing is a measurement challenge, not a content issue, and requires data that AI does not possess.
The scale of AI-related failures is well documented:
- 50% of generative AI projects are abandoned after proof of concept — up from Gartner's original 2024 prediction of 30%, revised by Gartner itself in January 2026 ("Why 50% of GenAI Projects Fail," Gartner, January 2026)
- 60% of companies generate no material value from AI despite considerable investments (BCG, "The Widening AI Value Gap," September 2025, n=1,250 executives)
- 95% of enterprise AI pilots show zero financial return (MIT, "The GenAI Divide: State of AI in Business 2025," July 2025)
- Only 1% of companies consider themselves mature in AI deployment (McKinsey, "Superagency in the Workplace," January 2025)
These failures are systemic and not limited to pricing. Factors such as a lack of proprietary data, inadequate quality controls, and unclear business value are even more critical in pricing, where mistakes can result in loss of brand value, loss of customer trust and significant financial losses.
---
2. What AI Gets Right
It is important to acknowledge AI’s strengths. Dismissing AI entirely is as unwise as relying on it without proper evaluation.
AI excels at:
- Synthesis and pattern recognition. AI can scan thousands of competitor pricing pages, review transcripts, and market reports faster than any human team. It identifies themes, clusters similar data points, and surfaces patterns that would take weeks to find manually.
- Theory creation. When exploring a new market or evaluating pricing architecture options, AI can generate plausible hypotheses worth testing. This accelerates the early stages of pricing strategy.
- Data quality screening. AI-powered quality checks can identify pattern responses, speed-throughs, and contradictory answers in survey data with greater consistency than manual review. At Sjofors & Partners, our data pipeline uses 12+ AI-driven quality tests, disqualifying 90-95% of initial respondents before a single data point enters the analysis.
- Known-category estimation. Only, and this means only, for well-established products in well-documented categories, LLMs can produce WTP estimates that roughly match published market research (Brand, Israeli & Ngwe, Harvard Business School Working Paper 23-062, revised October 2025). This is because extensive pricing discussion already exists in their training data. This data is missing for most brands, for most products or services, and for all new products or services.
- Purchase intent approximation for known consumer products. In the strongest counter-evidence we found, PyMC Labs and Colgate-Palmolive demonstrated that Bayesian multilevel models using Semantic Similarity Ratings can reproduce purchase intent at 90% of human test-retest reliability across 57 consumer products (PyMC Labs / Colgate, 2025-2026). However, three critical caveats apply: (1) this worked for known consumer packaged goods where LLMs have extensive training data — not for novel B2B products or untested price points; (2) direct Likert-scale ratings from LLMs produced near-garbage results (0.26 distribution similarity vs 0.88 with their method), proving that naive strategies fail; and (3) the researchers themselves described their work as "augmentation, not replacement." The underlying data still originated from real buyer behavior.
- The interpolation-extrapolation boundary: AI performs well in the interpolation zone — established categories with known anchors, where historical data provides grounding. It fails in the extrapolation zone — net-new products, unfamiliar buyer utility functions, novel pricing models. In these cases, "AI produces self-assured yet uncalibrated narratives" because the training data lacks relevant examples (Sjofors & Partners, AI-Augmented Pricing Strategy 2026-2028). The newer the concept, the more you must rely on primary research for ground truth.
As the Harvard researchers concluded: "The gap between an LLM's predictions and actual purchaser preferences can lead to misleading results if a researcher simply replaces real data with AI-generated data or naively combines the two" (Brand, Israeli & Ngwe, HBS Working Paper 23-062).
---
3. The Five Gaps AI Cannot Close
Gap 1: No Primary Data (The Hallucination Problem)
LLMs do not measure anything. They predict the most probable next word in a sequence based on their training data. When asked "What would a mid-market SaaS buyer pay for X?", the model generates a plausible-sounding number drawn from blog posts, analyst reports, and forum discussions — not from actual buyer behavior.
The evidence is unambiguous:
- LLMs hallucinate in 3.3% to 13.6% of responses even when summarizing documents placed directly in front of them (Vectara Hallucination Leaderboard, updated May 2025). For open-ended queries without source documents — which is what a pricing question is — hallucination rates exceed 65% (PMC research).
- 40% of ChatGPT citations are completely fabricated.** In a B2B-specific study, only 69% of citations were both real and correctly attributed; 19% pointed to incorrect sources, and 12% referenced sources that did not exist at all (StudyFinds; PAN Communications).
- A peer-reviewed study in Marketing Science (INFORMS) found that "directly eliciting preferences using LLMs may yield misleading results." GPT models showed less patience than humans and produced discount rates "considerably larger than those found in humans" (Goli & Singh, Marketing Science 43(4), 2024).
- LLMs have zero access to proprietary WTP data. Conjoint analyses, Van Westendorp studies, Gabor-Granger tests, and Sjofors & Partners’ Predicted Demand Analysis™ are proprietary to the firms that commission them. This data never appears in LLM training corpora. When asked for pricing benchmarks, the model returns the most probable token sequence from public content — not verified market data (Towards Data Science).
- LLMs are structurally capped by the stated-preference ceiling. Economics distinguishes between stated preferences (what people say they would be willing to pay) and revealed preferences (what they actually pay). Research shows that revealed-preference models explain 49% of the observed variance in actual sales data, while the best stated-preference models explain only 32% (CEPR VoxEU; Samuelson, 1938; Kahneman & Tversky, 1979). LLMs can only synthesize stated-preference data — public commentary, reviews, and forum discussions. They have no access to transaction records showing what people really paid. This means LLM-based WTP estimates are mathematically capped at a lower accuracy ceiling than methods that incorporate actual purchase behavior.
- The global market research industry has formally rejected synthetic respondents. ESOMAR's Nik Samoylov concluded that synthetic respondents "generate unreliable results and face numerous sources of error, making them inappropriate for legitimate market research purposes," identifying five novel error types: training data error, training method error, RLHF error, prompting error, and inference parameter error (Samoylov, ESOMAR/Research World, 2024). Steven Millman of Quirks Marketing Research Review added that AI-generated synthetic data "cannot produce margins of error around their estimates, which makes statistical testing misleading at best" (Millman, Quirks, 2025).
Implication for pricing: When an LLM estimates willingness to pay, it generates a plausible but unverified figure. While the result may appear reasonable, it is not based on actual measurement. Relying on such estimates is equivalent to making an uninformed guess.
Gap 2: No Non-Buyers (The Missing Market Problem)
This is the most significant gap. No advancement in AI can address it, as the issue stems from data access rather than computational capability.
Your sales data only tells you about the people who said yes.
It provides limited signals — win/loss codes, deal stall patterns, price-point friction — but these are filtered through the biases of the reps who recorded them and the customers who chose to respond. It cannot tell you why the qualified buyers who evaluated you and chose a competitor made that decision, or what it would have taken to win them. AI trained on your CRM, your transaction records, and your support tickets inherits this same blind spot. It can optimize for the customers you already have. It is structurally blind to the customers you are missing.
The evidence for why this matters:
- Analysis of 10,247 post-decision buyer interviews found that 62.3% of buyers initially cite price as the reason they chose a competitor. After structured probing, price remains the actual primary driver in only 18.1% of cases — a 44-point gap between what buyers say and what actually drove their decision (User Intuition, January 2024 - December 2025).
- Sales reps attribute losses to price 48% of the time, buyers cite price as the primary factor only 23% of the time (Primary Intelligence, based on 50,000+ win-loss interviews).
- Only 28% of deals "lost to pricing" represent authentic budget constraints. The remaining 72% reflect value perception misalignment — a problem AI cannot diagnose without talking to the actual non-buyers (Clozd, analysis of 8,400 enterprise software deals).
AI cannot resolve this issue. While an LLM can simulate a non-buyer persona using demographic profiles, this results in generalized stereotypes rather than accurate measurements. The model does not reflect the specific qualified buyers in your market who evaluated your product and chose a competitor for reasons not captured in your data.
At Sjofors & Partners, we survey qualified buyers across the entire addressable market — including those who chose a competitor — through partnerships with research panels that cover 100M+ respondents globally. AI cannot do this. No amount of prompt engineering changes the fact that the model has never spoken to a non-buyer in your market.
Gap 3: No Price Walls (The Psychological Gap)
Human buying behavior is not linear. Demand does not decrease smoothly as price increases. Instead, it drops sharply at specific thresholds — what we call Price Walls.
Examples of Price Walls:
- A $9,500 B2B software product sells consistently. At $10,500, sales collapse — not because of a 10% price increase, but because the purchase now crosses a procurement threshold that triggers CFO approval, competitive bidding requirements, and a 90+ day additional sales cycle. The $10,000 line is not a price — it is a workflow trigger.
- A B2C product at $19.99 has strong volume. At $24.99, volume drops modestly. At $25.01, volume falls off a cliff — because buyers psychologically categorize it as "over $25" rather than "around $20."
These discontinuities are invisible to LLMs generating WTP estimates from public data because they arise from organizational procurement policies, psychological category boundaries, and institutional approval workflows — none of which exist in training corpora. The underlying behavioral economics is well established: Kahneman and Tversky's Prospect Theory (1979; Nobel Prize in Economics, 2002) demonstrates that human economic decisions are driven by cognitive and affective factors that text-prediction algorithms cannot model.
An important distinction: AI and machine learning can detect non-linear demand patterns — but only when applied to the right data. Revenue management systems in airlines and hotels detect price thresholds from historical booking data. E-commerce A/B testing platforms identify conversion cliffs from live experiments. But neither understands how these Price Walls can be moved, i.e., how a company can market itself so that WTP increases and prices can increase without crossing a Price Wall. And at Sjofors & Partners, our Predictive Demand Engine ™ uses AI to identify Price Walls from primary survey data collected from real buyers, including what affects buyers to change that psychological price point that is the Price Wall.
The key distinction lies in the data AI analyzes. AI trained on public internet data cannot detect Price Walls, whereas AI trained on proprietary primary research data can. In the augmented approach, the data source determines effectiveness, not the algorithm.
For new products, new price points, or untested price ranges, no amount of historical transaction data or LLM inference can identify Price Walls in advance. Survey-based approaches like the Predictive Demand Engine™ and, to some extent, the Van Westendorp and Gabor-Granger methods can identify them before going to market — giving you the data that makes AI analysis meaningful.
Gap 4: No Segment Precision (The Homogenization Problem)
Real markets contain sharp differences in WTP across segments. A feature worth $200/month to a 500-person company may be worth $2,000/month to a 5,000-person enterprise — and worth nothing to a 50-person startup. Pricing strategy depends on identifying these differences with precision.
LLMs flatten this complexity.
The peer-reviewed evidence:
- When LLMs simulate survey respondents, their responses show significantly less variation than real human data. Regression coefficients differ from real survey estimates, and the same prompt yields significantly different results over a 3-month period (Bisbee et al., "Synthetic Replacements for Human Survey Data? The Perils of Large Language Models," Political Analysis, Cambridge University Press, May 2024).
- Across 43 language models, survey responses are dominated by ordering and labeling biases. When these biases are corrected via randomized answer ordering, models produce uniformly random responses — regardless of model size or training data (Dominguez-Olmedo, Hardt & Mendler-Dunner, Max-Planck Institute for Intelligent Systems, October 2025).
- LLMs exhibit “structural inconsistency” across population segments and “homogenization” that underrepresents minority viewpoints by selecting majority/modal responses (Li, Li & Qiu, Northwestern Kellogg / Zhejiang University, June 2025).
- When persona-conditioned LLMs are compared to the 2024 General Social Survey across 52 attitudes, the LLMs generate belief systems that are "systematically over-constrained." Attitudes co-move too strongly, variance collapses onto a single axis, and beliefs become disproportionately predictable from demographics. Real people hold messy, multi-dimensional views that LLMs flatten (Barrie, 2026).
For pricing, this means LLM-generated willingness-to-pay estimates across segments may seem distinct but are based on stereotypes rather than actual data. As noted by Sjofors & Partners, an average price is the wrong price for everyone.
Gap 5: No Verified Quality (The Reproducibility Illusion)
Primary pricing research at Sjofors & Partners uses a rigorous Target → Screen → Scrub methodology:
- Target: We define the exact buyer profile using firmographic filters (industry, company size, revenue, geography), role-based criteria (title, function, seniority, decision-making authority), and behavioral markers (tech stack, purchase history, buying timeline).
- Screen: We ask questions only real buyers would know the answers to. Anyone who cannot answer correctly does not proceed.
- Scrub: 12+ AI-driven data quality tests remove pattern responses, speed-throughs, and contradictory answers before analysis starts.
Result: 90-95% of initial respondents are disqualified. Only qualified, engaged buyers with clean data inform the pricing recommendation.
LLMs have no equivalent quality gate. When a model generates a WTP estimate, there is no way to assess whether the "respondent" (the model) is qualified, engaged, or even coherent. A PNAS study found that AI agents can produce survey responses that pass standard attention checks at a 99.8% rate — meaning traditional quality controls cannot distinguish AI-generated responses from human ones (Westwood, Proceedings of the National Academy of Sciences 122(47), November 2025).
The assumption that a coherent response indicates a human respondent is no longer valid. Therefore, the data source is now more critical than ever.
Regarding reproducibility: Setting the temperature to zero and using structured prompts helps LLMs generate consistent outputs. However, reproducibility does not guarantee accuracy. The critical issue is whether the model’s answers reflect actual consumer actions, not just consistency.
---
4. When AI Pricing Goes Wrong: Case Studies
OpenAI Cannot Price OpenAI
In January 2025, OpenAI CEO Sam Altman publicly admitted: "Insane thing: we are currently losing money on OpenAI Pro subscriptions! People use it much more than we expected." He confirmed he "personally chose the price" of $200/month and "thought it would make money" (Fortune, January 2025).
The world's leading AI company — with more data science talent, compute resources, and market data than any other organization — could not price its own product correctly. The price was set by executive intuition, not research.
Zillow's $500M+ AI Pricing Catastrophe
Zillow's AI-powered home-buying algorithm caused the company to overpay for thousands of homes. The company took a $304 million inventory write-down in Q3 2021 alone (CNN Business), suffered total losses surpassing $500 million, laid off 25% of its workforce, and saw its market cap drop by $8 billion. As of March 2026, Zillow has not returned to iBuying (CitySignal, February 2026).
The failure was structural: the AI optimized on historical transaction data without understanding the psychological and financial dynamics that create non-linear price movements in real estate.
Cursor's $500M ARR Pricing Crisis
Cursor (>$500M ARR) changed its pricing in June 2025, leading users to run out of requests "after just a few prompts." CEO Michael Truell issued a public apology: "We recognize that we didn't handle this pricing rollout well and we're sorry" (TechCrunch, July 2025). The root cause: AI inference costs are inherently unpredictable, making cost-based pricing models fragile.
The Algorithmic Collusion Problem
When multiple competitors use the same AI models for pricing, they converge on the same prices. Harvard researchers found that LLM-based pricing agents "autonomously collude in oligopoly settings to the detriment of consumers," reaching prices 12-32% above competitive equilibrium within just 100 periods — far faster than classic algorithms (Fish, Gonczarowski & Shorrer, arXiv:2404.00806, revised March 2026; presented at AEA 2025).
This is not theoretical. The U.S. Department of Justice sued RealPage for AI-facilitated coordination of rental prices, resulting in 27 property firms paying $141 million to settle (DOJ filings, 2025). The FTC warned explicitly: "You can't use an algorithm to evade the law banning price-fixing agreements" (FTC, March 2024). Competition authorities in France, Germany, Denmark, Japan, Norway, Sweden, and the UK have launched parallel investigations into algorithmic pricing convergence (Springer, 2025; UK CMA, March 2026).
The pattern is clear: If AI is unable to reliably price products in data-rich domains such as AI services, real estate, or developer tools, it is unlikely to price your product accurately in your specific market.
---
5. The Augmented Approach: Primary Research + AI Analysis
The key question is not whether to use AI or research, but what data AI is analyzing.
The evidence for human-machine collaboration is strong:
- Autonomous AI agents achieve 32.5-49.5% lower success rates than humans working alone. But hybrid human-AI teams achieve the best outcomes of all (Stanford & Carnegie Mellon, November 2025).
- Companies using AI-assisted pricing strategies (not AI-replacing-research strategies) see revenue increases of 3-8% and profit margin improvements of up to 10% (McKinsey).
- Companies in the top quartile for revenue growth deploy AI for pricing twice as often as growth laggards — but as a tool augmenting human judgment, not replacing it (Bain & Company, September 2024, survey of 1,000+ commercial executives).
- Burke, Inc. built a custom GPT chatbot on Microsoft Azure-AI that engaged B2B respondents in conversational pricing negotiations. The AI replaced the survey instrument (improving the Gabor-Granger methodology), not the respondents. It moved respondents from System 1 (fast, automatic) to System 2 (slow, deliberate) thinking, producing more realistic pricing elasticity curves (Burke, Inc. / Microsoft, presented at ESOMAR Congress 2024).
This is how Sjofors & Partners uses AI:
1. AI-powered respondent qualification. Machine learning screens and disqualifies low-quality respondents across 12+ dimensions before analysis commences.
2. Predictive Demand Engine™ After collecting primary WTP data from qualified buyers across the full addressable market, our proprietary engine uses advanced clustering methods to identify:
- Distinct buyer personas through unsupervised segmentation
- Price Walls — non-linear demand discontinuities invisible to linear analysis
- Micro-segments where WTP diverges sharply from the market average
- Feature-level value drivers that justify premium positioning
3. AI-accelerated analysis. Pattern recognition across thousands of data points identifies correlations and anomalies faster than manual analysis — but always grounded in primary data from real buyers.
The distinction is that AI analyzes data collected from real, qualified buyers, including non-buyers, across global panels. AI improves the value of this data, but without it, there is nothing meaningful for AI to analyze.
---
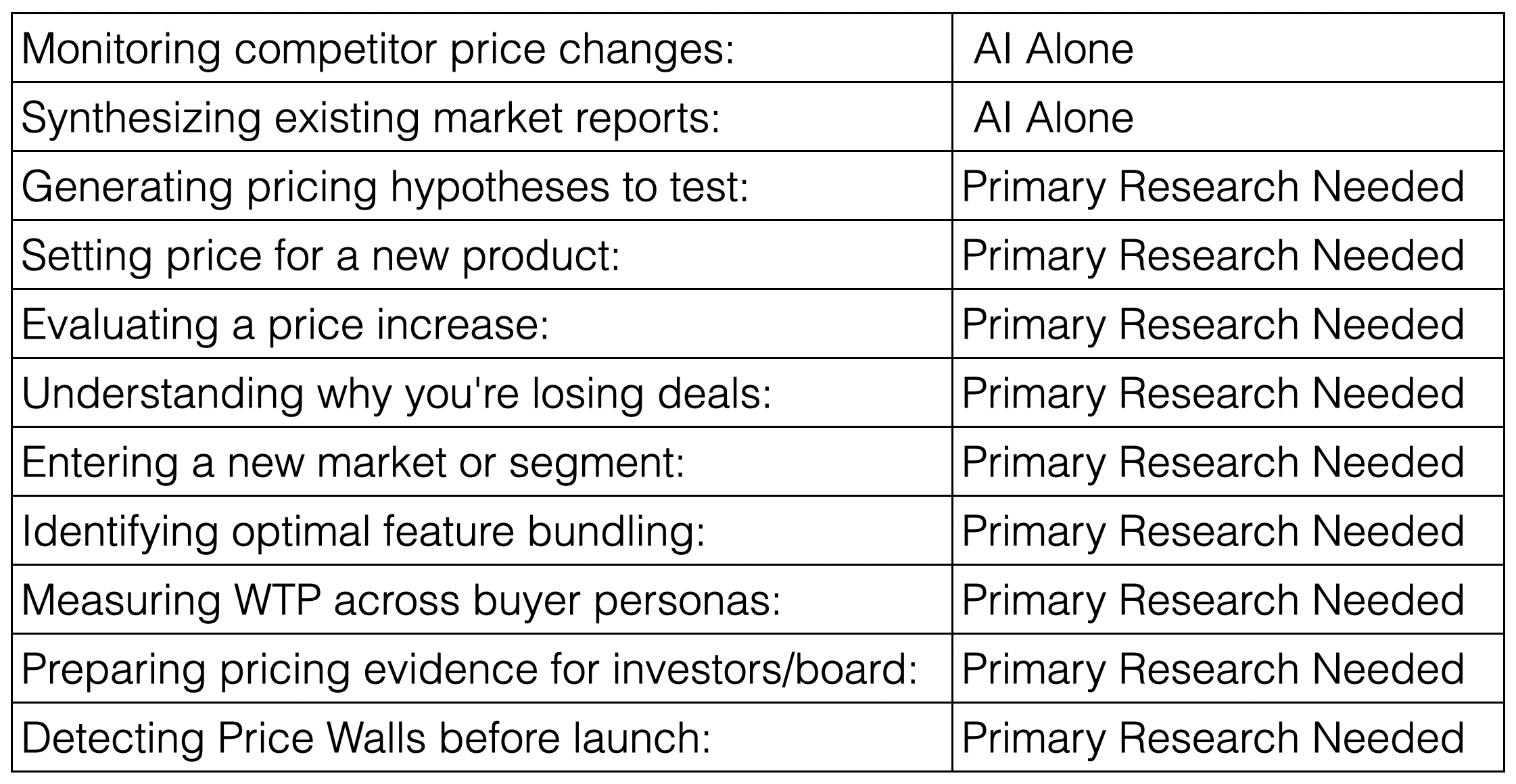
6. Decision Framework: When Do You Need Primary Research?
Scenario. Is AI Alone Sufficient, or is Primary Research Needed?
The Evidence-Based Case for Primary Pricing Research in the Age of Generative AI
By Per Sjofors, "The Price Whisperer"
Founder & CEO, Sjofors & Partners | Author, The Price Whisperer: A Holistic Approach to Pricing Power
April 2026
---
Executive Summary
For the average company, a 1% increase in pricing typically results in an 11% rise in operating profit (an easy calculation every company executive must do; see example below). Despite its impact, most companies do not fully leverage pricing as a profit driver.
In 2025-2026, more companies are turning to ChatGPT, Claude, and other large language models for pricing guidance, often replacing primary market research with AI-generated estimates. The appeal is clear: immediate answers, no cost, and no survey logistics.
However, this approach entails significant and predictable risks.
This document delivers peer-reviewed evidence supporting a straightforward thesis:
AI can analyze historical pricing data, but it cannot measure willingness to pay (WTP). No validated methodology exists for generating reliable WTP estimates for new products, price points, or segments without collecting primary data from real buyers and non-buyers in B2C or B2B.
This is not an anti-AI argument. Sjofors & Partners uses AI extensively — our Predictive Demand Engine™ applies advanced clustering methods, AI-powered data quality screening, and machine learning to identify concealed patterns in primary research data. AI makes our research more powerful, more comprehensive, more practical and more detailed.
However, AI cannot replace primary research. The following sections explain why.
---
1. The $1.1 Trillion Question
Every year, companies leave an estimated $1.1 trillion in value on the table through pricing errors (Simon-Kucher Global Pricing Study). Most pricing decisions are still based on three unreliable inputs: assumptions, competitor benchmarks, and cost-plus margins.
A fourth unreliable input has emerged: reliance on AI for pricing decisions.
The appeal is understandable. Generative AI has transformed content creation, code generation, and data synthesis. However, pricing is a measurement challenge, not a content issue, and requires data that AI does not possess.
The scale of AI-related failures is well documented:
- 50% of generative AI projects are abandoned after proof of concept — up from Gartner's original 2024 prediction of 30%, revised by Gartner itself in January 2026 ("Why 50% of GenAI Projects Fail," Gartner, January 2026)
- 60% of companies generate no material value from AI despite considerable investments (BCG, "The Widening AI Value Gap," September 2025, n=1,250 executives)
- 95% of enterprise AI pilots show zero financial return (MIT, "The GenAI Divide: State of AI in Business 2025," July 2025)
- Only 1% of companies consider themselves mature in AI deployment (McKinsey, "Superagency in the Workplace," January 2025)
These failures are systemic and not limited to pricing. Factors such as a lack of proprietary data, inadequate quality controls, and unclear business value are even more critical in pricing, where mistakes can result in loss of brand value, loss of customer trust and significant financial losses.
---
2. What AI Gets Right
It is important to acknowledge AI’s strengths. Dismissing AI entirely is as unwise as relying on it without proper evaluation.
AI excels at:
- Synthesis and pattern recognition. AI can scan thousands of competitor pricing pages, review transcripts, and market reports faster than any human team. It identifies themes, clusters similar data points, and surfaces patterns that would take weeks to find manually.
- Theory creation. When exploring a new market or evaluating pricing architecture options, AI can generate plausible hypotheses worth testing. This accelerates the early stages of pricing strategy.
- Data quality screening. AI-powered quality checks can identify pattern responses, speed-throughs, and contradictory answers in survey data with greater consistency than manual review. At Sjofors & Partners, our data pipeline uses 12+ AI-driven quality tests, disqualifying 90-95% of initial respondents before a single data point enters the analysis.
- Known-category estimation. Only, and this means only, for well-established products in well-documented categories, LLMs can produce WTP estimates that roughly match published market research (Brand, Israeli & Ngwe, Harvard Business School Working Paper 23-062, revised October 2025). This is because extensive pricing discussion already exists in their training data. This data is missing for most brands, for most products or services, and for all new products or services.
- Purchase intent approximation for known consumer products. In the strongest counter-evidence we found, PyMC Labs and Colgate-Palmolive demonstrated that Bayesian multilevel models using Semantic Similarity Ratings can reproduce purchase intent at 90% of human test-retest reliability across 57 consumer products (PyMC Labs / Colgate, 2025-2026). However, three critical caveats apply: (1) this worked for known consumer packaged goods where LLMs have extensive training data — not for novel B2B products or untested price points; (2) direct Likert-scale ratings from LLMs produced near-garbage results (0.26 distribution similarity vs 0.88 with their method), proving that naive strategies fail; and (3) the researchers themselves described their work as "augmentation, not replacement." The underlying data still originated from real buyer behavior.
- The interpolation-extrapolation boundary: AI performs well in the interpolation zone — established categories with known anchors, where historical data provides grounding. It fails in the extrapolation zone — net-new products, unfamiliar buyer utility functions, novel pricing models. In these cases, "AI produces self-assured yet uncalibrated narratives" because the training data lacks relevant examples (Sjofors & Partners, AI-Augmented Pricing Strategy 2026-2028). The newer the concept, the more you must rely on primary research for ground truth.
As the Harvard researchers concluded: "The gap between an LLM's predictions and actual purchaser preferences can lead to misleading results if a researcher simply replaces real data with AI-generated data or naively combines the two" (Brand, Israeli & Ngwe, HBS Working Paper 23-062).
---
3. The Five Gaps AI Cannot Close
Gap 1: No Primary Data (The Hallucination Problem)
LLMs do not measure anything. They predict the most probable next word in a sequence based on their training data. When asked "What would a mid-market SaaS buyer pay for X?", the model generates a plausible-sounding number drawn from blog posts, analyst reports, and forum discussions — not from actual buyer behavior.
The evidence is unambiguous:
- LLMs hallucinate in 3.3% to 13.6% of responses even when summarizing documents placed directly in front of them (Vectara Hallucination Leaderboard, updated May 2025). For open-ended queries without source documents — which is what a pricing question is — hallucination rates exceed 65% (PMC research).
- 40% of ChatGPT citations are completely fabricated.** In a B2B-specific study, only 69% of citations were both real and correctly attributed; 19% pointed to incorrect sources, and 12% referenced sources that did not exist at all (StudyFinds; PAN Communications).
- A peer-reviewed study in Marketing Science (INFORMS) found that "directly eliciting preferences using LLMs may yield misleading results." GPT models showed less patience than humans and produced discount rates "considerably larger than those found in humans" (Goli & Singh, Marketing Science 43(4), 2024).
- LLMs have zero access to proprietary WTP data. Conjoint analyses, Van Westendorp studies, Gabor-Granger tests, and Sjofors & Partners’ Predicted Demand Analysis™ are proprietary to the firms that commission them. This data never appears in LLM training corpora. When asked for pricing benchmarks, the model returns the most probable token sequence from public content — not verified market data (Towards Data Science).
- LLMs are structurally capped by the stated-preference ceiling. Economics distinguishes between stated preferences (what people say they would be willing to pay) and revealed preferences (what they actually pay). Research shows that revealed-preference models explain 49% of the observed variance in actual sales data, while the best stated-preference models explain only 32% (CEPR VoxEU; Samuelson, 1938; Kahneman & Tversky, 1979). LLMs can only synthesize stated-preference data — public commentary, reviews, and forum discussions. They have no access to transaction records showing what people really paid. This means LLM-based WTP estimates are mathematically capped at a lower accuracy ceiling than methods that incorporate actual purchase behavior.
- The global market research industry has formally rejected synthetic respondents. ESOMAR's Nik Samoylov concluded that synthetic respondents "generate unreliable results and face numerous sources of error, making them inappropriate for legitimate market research purposes," identifying five novel error types: training data error, training method error, RLHF error, prompting error, and inference parameter error (Samoylov, ESOMAR/Research World, 2024). Steven Millman of Quirks Marketing Research Review added that AI-generated synthetic data "cannot produce margins of error around their estimates, which makes statistical testing misleading at best" (Millman, Quirks, 2025).
Implication for pricing: When an LLM estimates willingness to pay, it generates a plausible but unverified figure. While the result may appear reasonable, it is not based on actual measurement. Relying on such estimates is equivalent to making an uninformed guess.
Gap 2: No Non-Buyers (The Missing Market Problem)
This is the most significant gap. No advancement in AI can address it, as the issue stems from data access rather than computational capability.
Your sales data only tells you about the people who said yes.
It provides limited signals — win/loss codes, deal stall patterns, price-point friction — but these are filtered through the biases of the reps who recorded them and the customers who chose to respond. It cannot tell you why the qualified buyers who evaluated you and chose a competitor made that decision, or what it would have taken to win them. AI trained on your CRM, your transaction records, and your support tickets inherits this same blind spot. It can optimize for the customers you already have. It is structurally blind to the customers you are missing.
The evidence for why this matters:
- Analysis of 10,247 post-decision buyer interviews found that 62.3% of buyers initially cite price as the reason they chose a competitor. After structured probing, price remains the actual primary driver in only 18.1% of cases — a 44-point gap between what buyers say and what actually drove their decision (User Intuition, January 2024 - December 2025).
- Sales reps attribute losses to price 48% of the time, buyers cite price as the primary factor only 23% of the time (Primary Intelligence, based on 50,000+ win-loss interviews).
- Only 28% of deals "lost to pricing" represent authentic budget constraints. The remaining 72% reflect value perception misalignment — a problem AI cannot diagnose without talking to the actual non-buyers (Clozd, analysis of 8,400 enterprise software deals).
AI cannot resolve this issue. While an LLM can simulate a non-buyer persona using demographic profiles, this results in generalized stereotypes rather than accurate measurements. The model does not reflect the specific qualified buyers in your market who evaluated your product and chose a competitor for reasons not captured in your data.
At Sjofors & Partners, we survey qualified buyers across the entire addressable market — including those who chose a competitor — through partnerships with research panels that cover 100M+ respondents globally. AI cannot do this. No amount of prompt engineering changes the fact that the model has never spoken to a non-buyer in your market.
Gap 3: No Price Walls (The Psychological Gap)
Human buying behavior is not linear. Demand does not decrease smoothly as price increases. Instead, it drops sharply at specific thresholds — what we call Price Walls.
Examples of Price Walls:
- A $9,500 B2B software product sells consistently. At $10,500, sales collapse — not because of a 10% price increase, but because the purchase now crosses a procurement threshold that triggers CFO approval, competitive bidding requirements, and a 90+ day additional sales cycle. The $10,000 line is not a price — it is a workflow trigger.
- A B2C product at $19.99 has strong volume. At $24.99, volume drops modestly. At $25.01, volume falls off a cliff — because buyers psychologically categorize it as "over $25" rather than "around $20."
These discontinuities are invisible to LLMs generating WTP estimates from public data because they arise from organizational procurement policies, psychological category boundaries, and institutional approval workflows — none of which exist in training corpora. The underlying behavioral economics is well established: Kahneman and Tversky's Prospect Theory (1979; Nobel Prize in Economics, 2002) demonstrates that human economic decisions are driven by cognitive and affective factors that text-prediction algorithms cannot model.
An important distinction: AI and machine learning can detect non-linear demand patterns — but only when applied to the right data. Revenue management systems in airlines and hotels detect price thresholds from historical booking data. E-commerce A/B testing platforms identify conversion cliffs from live experiments. But neither understands how these Price Walls can be moved, i.e., how a company can market itself so that WTP increases and prices can increase without crossing a Price Wall. And at Sjofors & Partners, our Predictive Demand Engine ™ uses AI to identify Price Walls from primary survey data collected from real buyers, including what affects buyers to change that psychological price point that is the Price Wall.
The key distinction lies in the data AI analyzes. AI trained on public internet data cannot detect Price Walls, whereas AI trained on proprietary primary research data can. In the augmented approach, the data source determines effectiveness, not the algorithm.
For new products, new price points, or untested price ranges, no amount of historical transaction data or LLM inference can identify Price Walls in advance. Survey-based approaches like the Predictive Demand Engine™ and, to some extent, the Van Westendorp and Gabor-Granger methods can identify them before going to market — giving you the data that makes AI analysis meaningful.
Gap 4: No Segment Precision (The Homogenization Problem)
Real markets contain sharp differences in WTP across segments. A feature worth $200/month to a 500-person company may be worth $2,000/month to a 5,000-person enterprise — and worth nothing to a 50-person startup. Pricing strategy depends on identifying these differences with precision.
LLMs flatten this complexity.
The peer-reviewed evidence:
- When LLMs simulate survey respondents, their responses show significantly less variation than real human data. Regression coefficients differ from real survey estimates, and the same prompt yields significantly different results over a 3-month period (Bisbee et al., "Synthetic Replacements for Human Survey Data? The Perils of Large Language Models," Political Analysis, Cambridge University Press, May 2024).
- Across 43 language models, survey responses are dominated by ordering and labeling biases. When these biases are corrected via randomized answer ordering, models produce uniformly random responses — regardless of model size or training data (Dominguez-Olmedo, Hardt & Mendler-Dunner, Max-Planck Institute for Intelligent Systems, October 2025).
- LLMs exhibit “structural inconsistency” across population segments and “homogenization” that underrepresents minority viewpoints by selecting majority/modal responses (Li, Li & Qiu, Northwestern Kellogg / Zhejiang University, June 2025).
- When persona-conditioned LLMs are compared to the 2024 General Social Survey across 52 attitudes, the LLMs generate belief systems that are "systematically over-constrained." Attitudes co-move too strongly, variance collapses onto a single axis, and beliefs become disproportionately predictable from demographics. Real people hold messy, multi-dimensional views that LLMs flatten (Barrie, 2026).
For pricing, this means LLM-generated willingness-to-pay estimates across segments may seem distinct but are based on stereotypes rather than actual data. As noted by Sjofors & Partners, an average price is the wrong price for everyone.
Gap 5: No Verified Quality (The Reproducibility Illusion)
Primary pricing research at Sjofors & Partners uses a rigorous Target → Screen → Scrub methodology:
- Target: We define the exact buyer profile using firmographic filters (industry, company size, revenue, geography), role-based criteria (title, function, seniority, decision-making authority), and behavioral markers (tech stack, purchase history, buying timeline).
- Screen: We ask questions only real buyers would know the answers to. Anyone who cannot answer correctly does not proceed.
- Scrub: 12+ AI-driven data quality tests remove pattern responses, speed-throughs, and contradictory answers before analysis starts.
Result: 90-95% of initial respondents are disqualified. Only qualified, engaged buyers with clean data inform the pricing recommendation.
LLMs have no equivalent quality gate. When a model generates a WTP estimate, there is no way to assess whether the "respondent" (the model) is qualified, engaged, or even coherent. A PNAS study found that AI agents can produce survey responses that pass standard attention checks at a 99.8% rate — meaning traditional quality controls cannot distinguish AI-generated responses from human ones (Westwood, Proceedings of the National Academy of Sciences 122(47), November 2025).
The assumption that a coherent response indicates a human respondent is no longer valid. Therefore, the data source is now more critical than ever.
Regarding reproducibility: Setting the temperature to zero and using structured prompts helps LLMs generate consistent outputs. However, reproducibility does not guarantee accuracy. The critical issue is whether the model’s answers reflect actual consumer actions, not just consistency.
---
4. When AI Pricing Goes Wrong: Case Studies
OpenAI Cannot Price OpenAI
In January 2025, OpenAI CEO Sam Altman publicly admitted: "Insane thing: we are currently losing money on OpenAI Pro subscriptions! People use it much more than we expected." He confirmed he "personally chose the price" of $200/month and "thought it would make money" (Fortune, January 2025).
The world's leading AI company — with more data science talent, compute resources, and market data than any other organization — could not price its own product correctly. The price was set by executive intuition, not research.
Zillow's $500M+ AI Pricing Catastrophe
Zillow's AI-powered home-buying algorithm caused the company to overpay for thousands of homes. The company took a $304 million inventory write-down in Q3 2021 alone (CNN Business), suffered total losses surpassing $500 million, laid off 25% of its workforce, and saw its market cap drop by $8 billion. As of March 2026, Zillow has not returned to iBuying (CitySignal, February 2026).
The failure was structural: the AI optimized on historical transaction data without understanding the psychological and financial dynamics that create non-linear price movements in real estate.
Cursor's $500M ARR Pricing Crisis
Cursor (>$500M ARR) changed its pricing in June 2025, leading users to run out of requests "after just a few prompts." CEO Michael Truell issued a public apology: "We recognize that we didn't handle this pricing rollout well and we're sorry" (TechCrunch, July 2025). The root cause: AI inference costs are inherently unpredictable, making cost-based pricing models fragile.
The Algorithmic Collusion Problem
When multiple competitors use the same AI models for pricing, they converge on the same prices. Harvard researchers found that LLM-based pricing agents "autonomously collude in oligopoly settings to the detriment of consumers," reaching prices 12-32% above competitive equilibrium within just 100 periods — far faster than classic algorithms (Fish, Gonczarowski & Shorrer, arXiv:2404.00806, revised March 2026; presented at AEA 2025).
This is not theoretical. The U.S. Department of Justice sued RealPage for AI-facilitated coordination of rental prices, resulting in 27 property firms paying $141 million to settle (DOJ filings, 2025). The FTC warned explicitly: "You can't use an algorithm to evade the law banning price-fixing agreements" (FTC, March 2024). Competition authorities in France, Germany, Denmark, Japan, Norway, Sweden, and the UK have launched parallel investigations into algorithmic pricing convergence (Springer, 2025; UK CMA, March 2026).
The pattern is clear: If AI is unable to reliably price products in data-rich domains such as AI services, real estate, or developer tools, it is unlikely to price your product accurately in your specific market.
---
5. The Augmented Approach: Primary Research + AI Analysis
The key question is not whether to use AI or research, but what data AI is analyzing.
The evidence for human-machine collaboration is strong:
- Autonomous AI agents achieve 32.5-49.5% lower success rates than humans working alone. But hybrid human-AI teams achieve the best outcomes of all (Stanford & Carnegie Mellon, November 2025).
- Companies using AI-assisted pricing strategies (not AI-replacing-research strategies) see revenue increases of 3-8% and profit margin improvements of up to 10% (McKinsey).
- Companies in the top quartile for revenue growth deploy AI for pricing twice as often as growth laggards — but as a tool augmenting human judgment, not replacing it (Bain & Company, September 2024, survey of 1,000+ commercial executives).
- Burke, Inc. built a custom GPT chatbot on Microsoft Azure-AI that engaged B2B respondents in conversational pricing negotiations. The AI replaced the survey instrument (improving the Gabor-Granger methodology), not the respondents. It moved respondents from System 1 (fast, automatic) to System 2 (slow, deliberate) thinking, producing more realistic pricing elasticity curves (Burke, Inc. / Microsoft, presented at ESOMAR Congress 2024).
This is how Sjofors & Partners uses AI:
1. AI-powered respondent qualification. Machine learning screens and disqualifies low-quality respondents across 12+ dimensions before analysis commences.
2. Predictive Demand Engine™ After collecting primary WTP data from qualified buyers across the full addressable market, our proprietary engine uses advanced clustering methods to identify:
- Distinct buyer personas through unsupervised segmentation
- Price Walls — non-linear demand discontinuities invisible to linear analysis
- Micro-segments where WTP diverges sharply from the market average
- Feature-level value drivers that justify premium positioning
3. AI-accelerated analysis. Pattern recognition across thousands of data points identifies correlations and anomalies faster than manual analysis — but always grounded in primary data from real buyers.
The distinction is that AI analyzes data collected from real, qualified buyers, including non-buyers, across global panels. AI improves the value of this data, but without it, there is nothing meaningful for AI to analyze.
---
6. Decision Framework: When Do You Need Primary Research?
Scenario. Is AI Alone Sufficient, or is Primary Research Needed?